
Kindle、honto、BOOK☆WALKER……複数の電子書籍ストアで本を買っていると、「あれ、この本もう持ってたっけ?」という瞬間がやってきます。
私もまさにその状態でした。数百冊の蔵書がバラバラのストアに散らばっていて、全体像がまったく見えない。そこで、購入完了メールから書籍情報を自動抽出し、Googleスプレッドシートに一元管理することにしました。
今回は、このシステムの設計思想と、開発中に直面した「意外な壁」について書いていきます。
この開発の流れだけ把握しておけば、Antigravity(無料のAIコードエディター)で同じ仕組みは簡単に作れますので、参考にしてください。
やりたかったこと
ゴールは非常にシンプルです。
- 複数ストアの書籍を1つのスプレッドシートで管理したい
- 新しい本を買ったらなるべく手間なくリストに追加したい
- でも無料お試し版など不要なものは自分で選別したい
完全自動化ではなく「半自動」という選択をしたのは、3つ目の要件があったからです。購入メールには無料お試し版も含まれるため、自分の意思で「これは登録する」と選べる仕組みが必要でした。
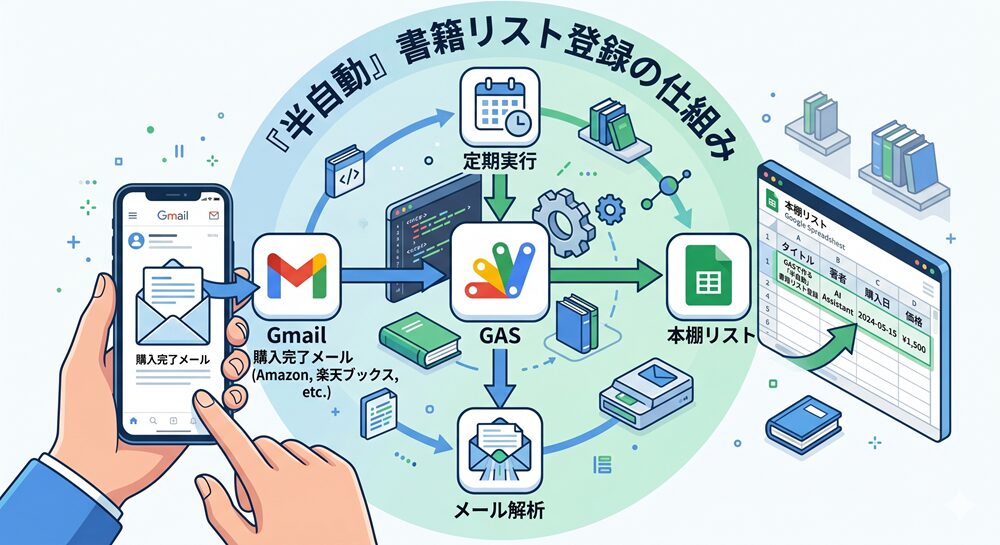
完成したシステムの全体像
最終的に出来上がったシステムは、2つのフェーズから構成されています。
フェーズ1:既存蔵書の一括取り込み(ブックマークレット)
過去に購入した数百冊の書籍は、各ストアの管理画面からJavaScriptで直接データを抽出しました。3つのストアそれぞれ専用のスクリプトを作成し、ブラウザのコンソールから実行してGAS(Google Apps Script)のWebアプリに送信する仕組みです。
フェーズ2:新規購入の半自動登録(GAS × Gmail)

こちらが本記事のメインです。日々の運用はたったの1アクションで完結します。
- 書籍を購入すると、Gmailに購入完了メールが届く
- そのメールに「登録」ラベルを付ける(不要なものはスルー)
- GASが毎朝自動チェックし、スプレッドシートに追記
処理済みメールには自動で「book_registered」ラベルが付くため、二重登録の心配もありません。
苦労したポイント① ― メール解析の「沼」
最初に試みたのは、Gmailの購入メールから正規表現でタイトルを抽出する方法でした。しかし、これが想像以上に難しかったのです。
同じストアでもメール形式が違う
例えばAmazon Kindleの場合、購入完了メールには日本語版と英語版が混在していました。
- 「
注文日: 2026年4月26日」と書かれているメール - 「
Placed on 2026年4月26日」と書かれているメール - タイトルの直後に「
販売者:」と来るもの - 「
Sold By:」と来るもの
購入時期によってフォーマットが異なるため、両方のパターンに対応する必要がありました。
hontoの「おすすめ商品」トラップ
hontoのメールでは、購入商品の後に「お客様へのおすすめ商品」というセクションが続きます。これを切り分けないと、買ってもいない本までリストに入ってしまいます。
さらに厄介だったのは、ブラウザで見るHTML版メールとGASが取得するプレーンテキスト版で構造が全く異なっていたこと。HTML版では「商品名」という見出しの下にタイトルが並びますが、プレーンテキスト版では【商品】というマーカーの後にタイトル名という形式でした。
この違いに気づくまでかなりの時間を要しました。
苦労したポイント② ― GASの実行制限との戦い
GAS(Google Apps Script)には最大6分という実行時間制限があります。この壁に何度もぶつかりました。
スター検索のパフォーマンス問題
当初は「スター★を付けたメールだけ処理する」という設計でした。直感的で分かりやすい仕組みですが、実際に動かしてみるとis:starred の検索に5分以上かかることが判明。過去のスター付きメールが多いほど、Gmailの内部走査が重くなるようです。
結局、スター方式を廃止し、専用の「登録」ラベルを使う方式に変更しました。新しいラベルは中身が空のため、検索が一瞬で終わります。
著者名はAPIで自動補完
Amazon Kindleのメールには著者名が含まれていないため、Google Books APIで自動補完することにしました。
既存の書籍を取り込む際には、一括処理する関係でAPIの通信制限やGASのタイムアウトに引っかかり、安定して動きませんでした。新規書籍の取り込み時は数件の取り込みですので、問題なく動作しました。
設計判断:なぜ「半自動」を選んだか
技術的にはGmail監視を完全自動化し、全メールを自動処理することも可能でした。しかし、あえて「登録」ラベルを手動で付けるという1アクションを残しました。
理由は明確です。
- 不要なデータの混入防止:無料お試し版や試し読みのメールを自動で弾くルールを完璧に作るのは困難
- 制御感:自分の本棚に何を入れるかは、自分で決めたい
- 運用コストの低さ:ラベルを付けるだけなので、数秒で終わる
「全自動」は魅力的ですが、「半自動」のほうが実用的で長続きするケースもあると実感しました。
技術スタック
| 用途 | 技術 |
|---|---|
| データ保存 | Google スプレッドシート |
| メール解析・自動登録 | Google Apps Script (GAS) |
| 既存データ抽出 | JavaScript(ブラウザコンソール実行) |
| 著者名補完 | Python + Google Books API |
まとめ

シンプルに見えるシステムですが、実際に作ってみるとメール形式の違い・API制限・ストアごとのUI差異など、予想外の壁が数多くありました。
特に印象的だったのは、「メールのHTML版とプレーンテキスト版で構造が異なる」という発見です。普段何気なく読んでいるメールも、裏側では複数のフォーマットが共存しているのだと改めて認識しました。
完璧を目指すとキリがないので、「完璧よりも実用的」を基準に判断を重ねました。著者名の自動補完をGASから切り離したのも、スター方式からラベル方式に切り替えたのも、すべて「確実に動く」ことを優先した結果です。
私の場合は3つのストアで700行(シリーズまとめ買いは1行に整理)ほどのリストになりましたが、思考錯誤しながらも、すべての作業を半日ほどで終えることができました。半日と言ってもAntigravityが作業を行っていたため、その間は他のことをしながらといった感じでした。
一度整理してしまえば、今後はずっとこの仕組みで整理できますから、同じように蔵書管理に悩んでいる方の参考になれば幸いです。
