
「どっちが優れているか」という議論は無意味
ここ数年、AI活用の議論において、しばしば「高性能なサーバーAI(クラウドAI)」と「レスポンスの良いエッジAI(オンデバイスAI)」が比較対象として語られてきました。
「クラウドこそが至高の知能(AGI)への道だ」という意見もあれば、「プライバシーと速度を考えればエッジこそが本命だ」という反論もあります。
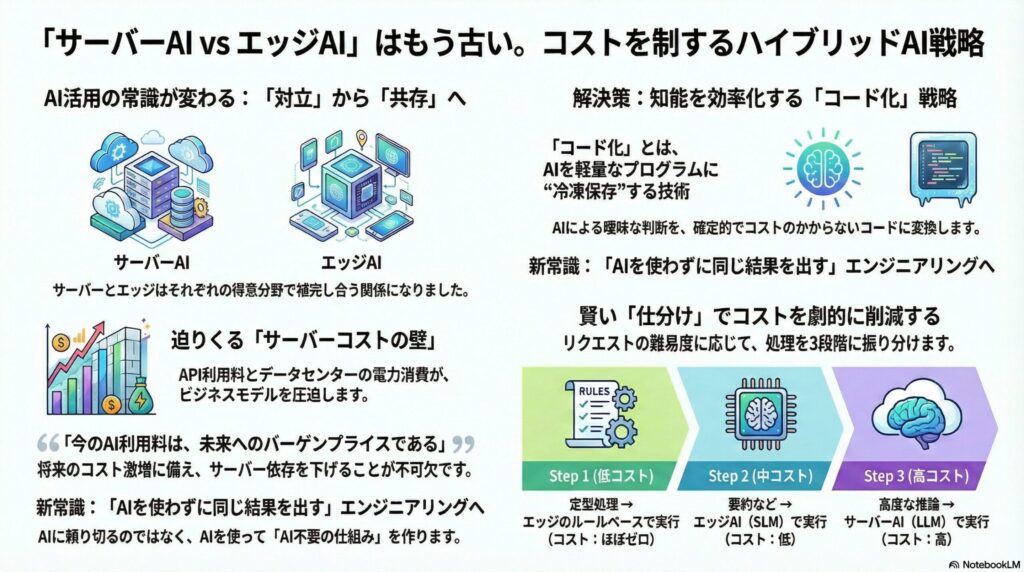
しかし、2026年を迎えた今、この二つはもはや「VS(対立)」の関係で語るべきではありません。答えは明確に「ハイブリッド(共存)」に定まっています。
コンピューティングの歴史を振り返れば、メインフレーム(集中)からPC(分散)、クラウド(集中)からエッジ(分散)へと、振り子は常に揺れ動いてきました。そして今、その振り子は「集中と分散のベストミックス」という平衡点に留まろうとしています。
なぜなら、すべての処理をサーバーに投げればコストとレイテンシが青天井になり、すべてをエッジで行おうとすればハードウェアリソースと知能の限界に直面するからです。
本記事では、これからのAI開発のスタンダードとなる「ハイブリッド構成」の必然性と、そこで最も重要な戦略となる「コード化(Codification)」—AIの知能を、確実で軽量なプログラムコードへと”冷凍保存”する技術—について深く掘り下げて解説します。
1. ハイブリッド共存が「しばらく続く」構造的理由
「いつかスマホの性能が上がれば、全てエッジで処理できる」あるいは「通信革命(6G等)が起きれば、全てクラウドで遅延なく処理できる」という極論は、物理的な制約を無視しています。
現状の技術トレンドを見ても、サーバーAIとエッジAIは、それぞれの得意領域で明確な役割分担を確立しており、この補完関係は今後5~10年は続く「確実な未来」です。
サーバーAIの独壇場:圧倒的な「知能」と「創造性」
数千億〜数兆パラメータを持つ巨大言語モデル(LLM)は、サーバーサイドでしか動きません(少なくともバッテリー駆動のデバイスでは不可能です)。
サーバーAIの役割は、「未知の事象への対応」と「高度な推論」です。例えば、複雑な契約書のリーガルチェック、全く新しいマーケティングコピーの生成、あるいは因果関係が複雑に入り組んだデータ分析など、文脈の長さと知識の深さが求められるタスクは、引き続きクラウドの独壇場です。
エッジAIの独壇場:圧倒的な「速度」と「プライバシー」
一方で、エッジAI(NPU搭載PC、スマホ、IoTデバイス)には、サーバーには絶対に真似できない強みがあります。
- 絶対的な低遅延(Real-time Latency):
例えば、自動運転車が「歩行者が飛び出した」と判断するのに、クラウドへ画像を送信して判定を待っていれば事故になります。スマートグラスでの翻訳も、0.5秒のラグがあるだけで会話のテンポは崩壊します。物理法則として、通信を介さないエッジ処理の速さには勝てません。 - プライバシーとセキュリティ (Data Sovereignty):
会議の録音データや、工場の生産ラインの映像、ヘルスケアデータなど、社外(クラウド)に出したくないデータは無数に存在します。「データが発生した場所で処理し、結果だけを保存する」というエッジのアプローチは、セキュリティ要件の厳しい現代において必須条件となりつつあります。 - 常時接続への非依存(Offline Availability):
災害時や電波の届かない地下、あるいは通信コストを抑制したい環境下でも、機能が停止しないことはBCP(事業継続計画)の観点からも重要です。
2. 迫りくる「サーバーコストの壁」と「グリーントランスフォーメーション」
「知能」は高い
ChatGPTの登場初期、多くの企業が「APIを叩けば何でもできる」と飛びつきました。しかし、PoC(概念実証)から実運用フェーズに移り、ユーザー数が数万、数百万人規模になった途端、多くのプロジェクトが「API利用料の壁」に衝突しました。
高性能なモデルは、トークンあたりの単価が高く、すべてのユーザーインタラクションをサーバーで処理していては、利益率が圧迫され、ビジネスモデルが破綻してしまいます。
現在は「普及のためのバーゲンプライス」であるという事実
現在、私たちは月額20ドルや、1トークンあたり数セントという価格で最先端のAIを利用できています。しかし、これは「適正価格」ではありません。
市場トップシェアを誇るOpenAIでさえ、現在は赤字覚悟の投資フェーズにあり、巨額の計算リソースコストを負担しながらサービスを提供しています。これは言わば、生成AIを社会に普及させるための「バーゲンプライス」なのです。
将来、AIが社会インフラとして完全に浸透し、なくてはならない存在になった時、何が起きるでしょうか。
当然、企業は投資回収フェーズに入ります。競争の沈静化に伴う値上げや、従量課金の厳格化など、AI利用コストが現在とは比較にならないほど跳ね上がる「コスト激増の未来」が予想されます。
その時になって初めて「エッジで処理できない構造」に気付いても、もう手遅れです。今のうちからサーバー依存度を下げる設計をしておくことは、将来の経営リスク回避そのものなのです。
電力という新たな制約
さらに深刻なのが電力消費です。データセンターの電力消費量は世界的に急増しており、「生成AIでの検索は、従来のGoogle検索の10倍以上の電力を消費する」とも言われています。
ESG経営が求められる中、「無駄にリッチなAI」を使い続けることは、コストだけでなく環境負荷の観点からも許されなくなりつつあります。
「必要な時に、必要なだけの知能を使う」という最適化は、企業の社会的責任でもあるのです。
3. 解決の鍵:「コード化(Codification)」によるエッジ処理の最適化
では、どうすればサーバー依存を脱却し、コストを下げられるのか。
その答えこそが、「コード化(Codification)」です。これは、「AIによる曖昧な判断を、確定的なプログラムコードに落とし込むプロセス」を指します。
これまでの「AI開発」は、プロンプトエンジニアリングによって「いかに賢いAIに良い答えを出させるか」に注力していました。しかしこれからの「AIエンジニアリング」は、「いかにリソースを使わずに同じ結果を出すか」にシフトします。
アプローチ①:蒸留(Distillation)とSLMの活用
まず考えられるのが、モデル自体のダウンサイジングです。
サーバー上の超巨大モデル(教師モデル)を使って、特定のタスク(例えば「カスタマーサポートの問い合わせ分類」や「領収書の読み取り」)専用のデータを大量に生成し、それを使って数億〜数十億パラメータ級の「小規模言語モデル(SLM)」を学習させます。
こうして作られたSLMは、汎用性こそありませんが、特定のタスクにおいては巨大モデル並みの精度を叩き出し、かつエッジデバイス上でサクサク動作します。これは「知能の圧縮」とも言えるアプローチです。
アプローチ②:ロジックの抽出と「確定的なコード」への変換
さらに踏み込んだアプローチが、完全な「コード化」です。
例えば、AIに「この文章から日付を抽出して」と頼むとします。LLMは毎回考え、そしてたまに間違えます。しかし、LLMを使って「日付抽出のための正規表現パターン」や「Pythonスクリプト」を一度生成させてしまえば、その後の処理にAIは不要です。
「AIを使って、AIを使わないプログラムを作る」。
このメタ的な自動化こそが、コストを限りなくゼロに近づける究極のハックです。
変動する入力に対してはAIが判断し、パターン化できる処理は即座にロジックとして固定化する。この「流動的な知能」と「固定的なロジック」の変換サイクルを回せる組織が、圧倒的なコスト競争力を持ちます。
アプローチ③:インテリジェント・ルーターの実装
ユーザーのすべて入力に対して、いきなり高性能なサーバーAIを呼ぶ必要はありません。
エッジ側で軽量なモデルが待ち構え、入力を3段階に振り分ける「ゲートウェイ(ルーター)」を配置します。
- Level 1 (エッジ処理/ルールベース):
「画面を明るくして」「ボリューム下げて」といった定型コマンドや、正規表現で処理可能なタスク。即座にデバイス内で実行。(コスト:ほぼゼロ) - Level 2 (エッジAI/SLM):
「届いたメールを3行で要約して」といった、やや高度だがパラメータ数の少ないモデルで対応可能なタスク。(コスト:低) - Level 3 (サーバーAI/LLM):
「このメールの文脈と過去のプロジェクトの経緯を踏まえて、礼儀正しい返信案を3つ考えて」といった、高度な推論と外部知識が必要なタスク。(コスト:高)
このように、リクエストの難易度に応じて適切な処理系にルーティングすることで、ユーザー体験(レスポンス速度)を維持しつつ、サーバーコストを劇的に(例えば10分の1に)削減することが可能になります。
4. 今後の展望:NPUネイティブ時代の到来について
IntelのCore Ultra、AppleのMシリーズチップ、そしてQualcommのSnapdragon X Eliteなど、PC向けのプロセッサにも強力なNPUが搭載されることが当たり前になりました。
これは、これまでサーバーで行っていた推論処理の大部分を、クライアントサイドにオフロードできる準備がハードウェアレベルで整ったことを意味します。
これからのソフトウェア開発では、以下のような設計が標準化していくでしょう。
- アプリには数GB程度のSLMが同梱され、インストールされる。
- ユーザーの操作データや個人設定は、ローカルのSLMが学習・微調整(Fine-Tuning)し、個々人に最適化された「自分専用AI」へと育っていく。
- 本当に困った時だけ、インターネットの向こう側の「巨人の肩(クラウドAI)」を借りる。
結論:正確さとコストのバランスを設計する「アーキテクト」へ
「AIにとりあえず投げれば良い」という思考停止の時代は終わりました。
これからのエンジニアやサービス責任者に求められるのは、プロンプトを書く力だけではありません。
サーバーAIが持つ無限の「知能」と、エッジ処理が持つ現実的な「効率」を組み合わせ、コストを最小化しつつ提供価値を最大化するアーキテクチャを設計する力です。
AIの曖昧な処理を、正確で軽量な「コード」へと落とし込んでいく技術力。
それは一見すると地味な最適化作業に見えるかもしれませんが、AIが社会インフラとして定着していく過渡期において、最も価値のあるスキルセットになることは間違いありません。
サーバーとエッジ、AIとコード。対立ではなく、それらを自在に操る「ハイブリッドな視点」こそが、これからの技術者の最強の武器となるのです。

